MOSARCH Home | Contributors | Publications | Toolset
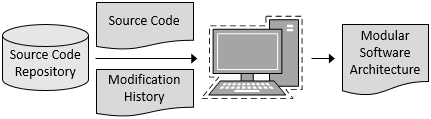
Our toolset aims at software architecture recovery by automatically clustering software modules for increasing modularity and supporting maintainability. The following figure depicts the system overview, where two types of data retrieved from the source code repository are used as input. The first one is the source code, which is analyzed to reveal dependencies among software modules. The second one is the modification history, which reveals software modules that are (often) modified together.
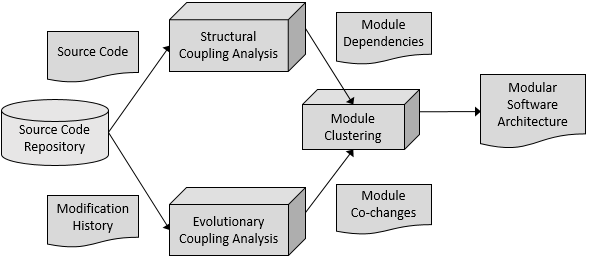
The main processes and the flow of (intermediate) artefacts are depicted in the figure below. There are 3 main processes. The first one performs Structural Coupling Analysis to extract Module Dependencies by analyzing the Source Code. There are several external tools such as Class Dependency Analyzer and jdeps that can perform this analysis and provide a module dependency graph. We compiled a dataset that includes a set of such graphs extracted from real systems. Most of these systems were used as experimental objects in previous empirical studies and their module dependency information is made available by other researchers online. The second process extracts Modification History from the Source Code Repository to analyze Module co-changes. We developed a repo mining tool that performs this analysis and provides a module dependency graph based on these co-changes. The last process performs Module Clustering based on the output artefacts of the other two processes.
The following figure depicts the envisioned design for the tool that performs Module Clustering for supporting extendability. The main component of the tool is Architecture Recovery, which takes a set of Dependency Models as input. These models can be extracted as a result of the analysis of either structural or evolutionary coupling regarding the modules of the subject system. In principle, the tool is agnostic to the programming language used for implementing the software system. Each dependency model focuses on a particular type of dependency and it includes the name of a set of modules involved in the system together with interdependencies among these modules. An additional input, Configuration Settings, is provided for configuring the clustering algorithm and its parameters. The output is the Clustering Result, which suggests an expected structural decomposition of a modular software architecture.
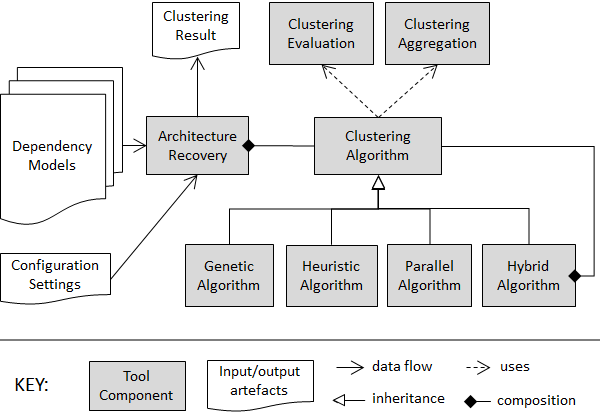
Two design patterns are adopted in the design depicted above. First, Strategy pattern is used for enabling the Architecture Recovery component to switch among various clustering algorithms. Second, Composite pattern is used for enabling the composition of algorithms to implement a hybrid algorithm. Clustering Algorithm is the base (abstract) class, which makes use of two other classes: i) Clustering Evaluation implements the calculation of metrics to measure the quality of a clustering, and ii) Clustering Aggregation implements algorithms for aggregating multiple clustering solutions into one. 3 concrete classes are implemented for clustering algorithms: i) Genetic Algorithm that implements an evolutionary approach for obtaining clustering solutions with respect to the considered metrics, ii) Heuristic Algorithm that implements a greedy algorithm, iii) Parallel Algorithm that implements several components of the evolutionary approach to be executed in parallel, and iv) Hybrid Algorithm that combines the other three approaches. Our experimental results suggest that the parallel hybrid algorithm outperforms the other state-of-the-art algorithms for architecture recovery.